Introduction
Paying only for legitimate claims is important for insurance companies. Traditionally, insurance companies have relied on claims assessors to identify claims anomalies and ascertain the legitimacy of claims. The process can be plagued by a complicated system, one that involves laborious manual procedures. The industry, however, continues to evolve, with ongoing technological advancements and improvements in the way we extract insights from data. Using machine learning techniques, we can identify patterns that may be missed by claims assessors and improve the efficiency of their claims processing. This article will describe the types of claims data typically available and the corresponding machine learning techniques for claims anomaly detection.
Data Considerations
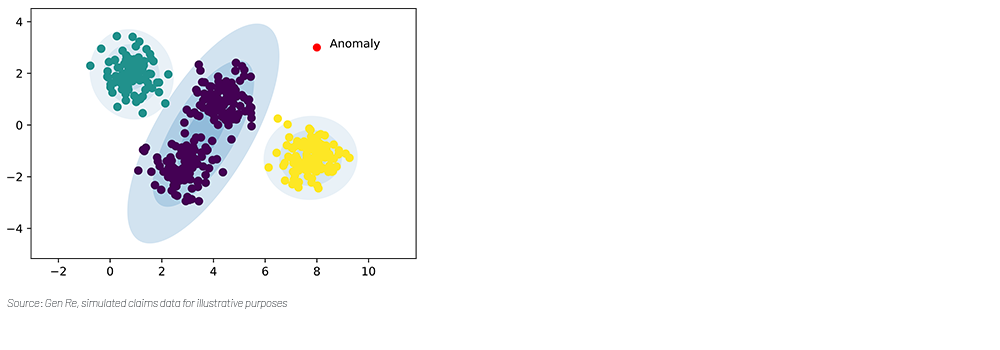
The number of features for insurance claims data is generally more limited when compared to anomaly detection problems in other contexts. Using autonomous driving as an example, data associated with anomaly detection are images. For a 256X256 image, the number of pixels amounts to 65536, which dwarfs the number of features we typically have in insurance data. Consequently, claims anomaly detection is generally more challenging.
One obvious solution is to collect more data. For health insurance claims, these data could be the hospital code, a doctor’s code, a drug prescription code, the cost of prescriptions, etc., data which are potentially predictive of an anomalous claim. However, this data strategy does not solve the immediate problem of having limited features for anomaly detection. We can make the best use of existing data by adopting the following strategies.
Data feature engineering
We can create more data features using existing claims data. For example, we can use our existing claims history database to derive the number of historical claims for a particular claimant at the point of making a new claim. It can be unusual for a claimant to be repeatedly claiming over a period. Creating such potentially predictive data features will enable the model to flag this claim.
Tapping into Large Language Models (LLMs)
We can derive meaningful representation of our textual data features by tapping into Large Language Models (LLMs), consequently deriving potentially predictive data features. For example, insurance companies would typically capture claims causes as free-text descriptions. We can capitalize on the rich clinical information captured in this text by leveraging LLMs, which have already been trained on vast amounts of data including medical- and insurance-related content.
An embedding is a numerical representation of words that capture its meaning and context in the form of a numeric vector. Drawing embeddings from an appropriate LLM, which better captures the contextual information of our text, will provide a better representation of the text data. For example, an LLM trained using medical literature produces embeddings which appropriately capture the semantic meaning of claims cause descriptions in the medical context.
To illustrate capturing semantic meaning, we drew the embeddings from an LLM to derive the representation of the following texts in the form of a numeric vector for each claim cause.
- Mammary gland tumor
- Breast cancer
- Depression
- Monday morning
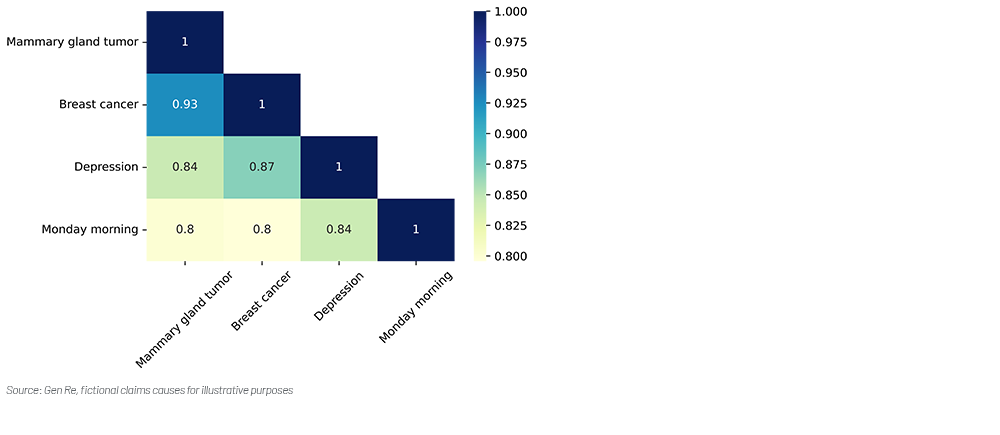
We would expect a good representation would identify that both mammary gland tumor and breast cancer have similar semantic meaning in the medical context. The comparison of representations for other texts have been provided for reference.
To measure the similarity of the textual representations in the form of numeric vectors, we use cosine similarity as the metric. Value “1” indicates perfect similarity, while “0” indicates no similarity.
Example: Mammary gland tumor and breast cancer
LLMs: Captured the contextual similarity evidenced by the high cosine similarity.
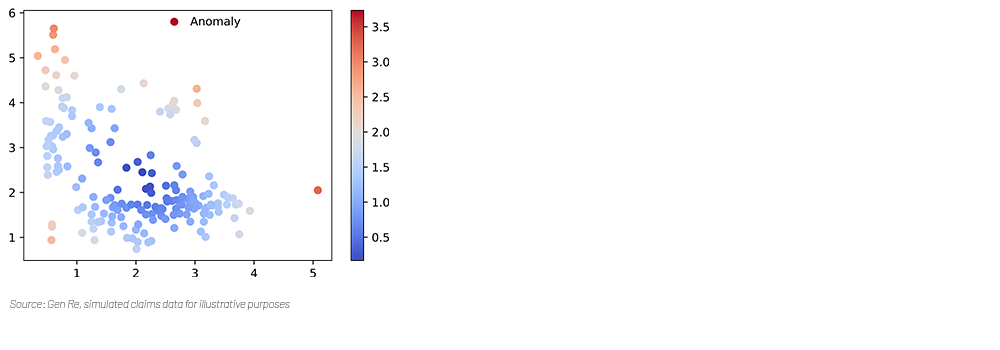
Figure 1 – Cosine similarities of text representation from Large Language Model (LLM)