In today’s challenging economy, insurance CEOs and managers face the difficult task of controlling costs and allocating resources and capital effectively, all in the face of disruption and competition. Data-driven insights are a competitive force, and the ability to gather actionable insights - and to act timely upon them - may determine a P&C (re)insurance carrier’s fate. Using free (open source) software allows carriers to develop data driven insights while controlling costs.
Carriers that are forward-looking increasingly rely on new sources of data and advanced analytics methods. One such source of insights is text mining outcomes. Mining of unstructured data provides carriers with a better understanding of their claims, with benefits that include:
- Understanding the correlation of frequency and/or severity with certain claim attributes (e.g., age of driver, type of injury, litigation)
- Minimizing missed financial opportunities
- Detecting potentially fraudulent claims
- Deriving actionable insights from customer feedback
As a reinsurance provider, the Gen Re advantage is having a volume of claims available to us to extract information. As we actively leverage claim narratives as well as associated PDF documents to derive insights, we believe our unique experience in setting up a text-mining process may be helpful to our clients in planning their own text-mining efforts.
Our process-driven approach is based on four basic principles and contains four major steps:
Process Principles
1. Start small, but think big. Find an area where there are business questions that need to be answered. Start with the information required to answer this question, but plan to expand beyond this area over time.
2. Bring text and structured data together quickly to derive insights.
3. Create easy-to-use visualizations for business consumption.
4. Create an end-to-end process where data is quickly refreshed with limited manual intervention.
Process Steps (Chart 1)
1. Data Ingestion - Hadoop is a set of open source programs and procedures that anyone can use as the backbone of their big data operations. It facilitates the integration of structured and unstructured data. Unstructured data ranges from First Notice of Loss and Claim Narratives to Legal Documents, and they are ingested into HDFS (Hadoop Distributed File System). They are then grouped based on the Line of Business for further processing. Structured financial data such as Paid Loss, Paid Expense and Reserves are ingested into Hadoop from relational databases, and then merged, aggregated and prepared to be combined with unstructured data.
2. Data Management - Unstructured data is often provided as scanned PDF documents. These require Optical Character Recognition (OCR) and Intelligent Character Recognition (ICR) to convert into machine-readable formats. After evaluating a number of commercial and open source tools, we narrowed down our solution to two open source tools. These offered the most accurate results. Python and/or PySpark scripts are used to OCR Scanned PDF documents in batches.
Structured data in HDFS is converted to raw data and then to transformed Hive tables to meet business needs.
One of the advantages of Hadoop is the thriving development community and plethora of open source tools that are compatible with Hadoop. One such example is Atlas which offers Data Governance and Data Lineage. Atlas provides a holistic approach to managing, improving and leveraging information to ensure consistency and builds confidence in the data being used.
3. Insights Generation - OCR performed PDF documents, along with other document types, are text-mined utilizing the Apache Spark framework on Hadoop. Text data is tokenized based on requirements after it is cleansed by removing stop words, punctuation and employing other techniques. Once the text-mined data is integrated with the structured financial information in Hive, it’s ready for insights generation. Hadoop can text mine documents at speeds far greater than traditional platforms allowing for efficient and quick delivery of actionable insights to the business.
4. Data Visualization - Data stored on an Apache Hive Database is accessed by data visualization software for insights generation and advanced analytics. This allows the business to use the visualization application to ask questions and find answers on their own.
Chart 1:
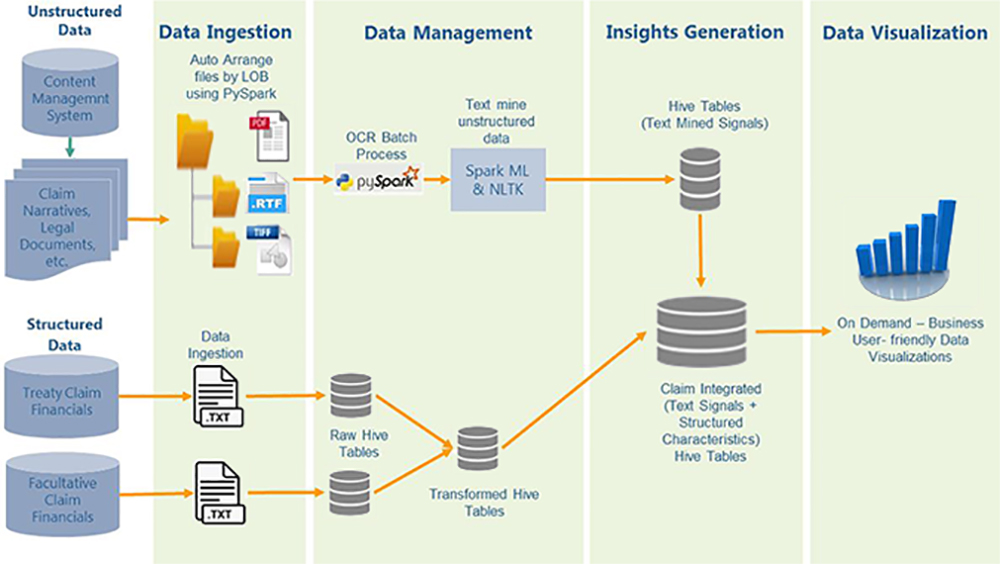
The entire process – from start to finish - is automated using open source workflow scheduling tools such as Oozie and Python. This makes the process seamless to the end user.
To learn more about how we use these tools and the process of deriving claims insights using text mining - or our Analytics Data Lake - please contact Gen Re’s Business Data and Analytics team through your Gen Re account executive. We’d be happy to talk with you.





















