In an earlier Risk Insights article, we examined the bold claim for big data that the abundance and speed of information would make knowledge redundant. We concluded that if knowledge is understood as the body of causal explanations for observed statistical correlations, there could indeed be a grain of truth in such a claim, especially in the field of commercial applications.
However, it is our view that future causal explanations will continue to enhance our confidence in the reliability and stability of statistical correlations. Whether or not to trust mere correlation without causal explanation becomes a practical issue to be dealt with on a case-by-case basis, weighing the benefits and risks. Before we take a closer look at such decision criteria, we will set out how big data contributes to social change that is already underway at an accelerating pace.
Keeping up with technological change
The digital revolution has intensified the technological acceleration begun during the industrial revolution. The acceleration has not increased leisure time, as might be expected to result from the efficiencies, for example, of air travel or electronic mail. Instead, it is continuously being outpaced by the acceleration of social change. Paradoxically, we suffer from increasing time pressure that, in turn, induces technological innovation and a further increase of its acceleration rate (see Figure 1). Technological and social change both form a self-propelling spiral of acceleration.1

The continuous acceleration of both technological and social change reduces our ability and confidence to predict the future. Put another way, the time span for which we can use past experience in order to make any authoritative statements about the likely future becomes continuously shorter.
We can speak of a contraction of the present (see Figure 2).2 The blue, red and orange rectangles represent the chronological past, present and future respectively.3 In preindustrial society governed by tradition, the innovation rate remains stable at a low level (grey line A). Past, present and future are more or less alike in terms of living conditions. Therefore, the present, which is understood as the time span for which we can use past experience in order to make any authoritative statements about the likely future, encompasses all three rectangles (A1 to A2) and the innovation rate stays within the margin of recognisability.
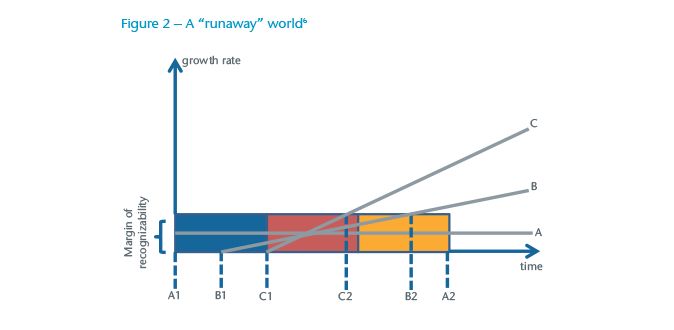
This time span can be called the semantic present (meaning) as opposed to the chronological present (time). The grey line B stands for the modern industrial era with increasing innovation rates. Consequently, we can only use a more recent past as a resource for predicting a not-too-distant future with any degree of confidence (time span B1 to B2). In the ongoing digital revolution, innovation rates have once again increased significantly, thus further contracting the semantic present (C1 to C2). Members of such high-speed societies increasingly feel that they are living in an uncontrolled “runaway” digital world.5
Keeping up with social change
The acceleration of social change poses a serious threat to life insurers. The correlations of risk factors and insured events, which are established in rather lengthy statistical analyses of data pools, must be revised faster than in the past. Generally speaking, pools will only generate significant results under two conditions:
- The data pools have a certain (minimum) size. The latter is composed of two factors: volume of data per unit of time (e.g. a year) times the number of units of time.
- The established correlations can safely be assumed to remain stable, not only during the observation period but, most importantly, for some time into the future.
The acceleration of social change undermines the second condition. It therefore necessitates shorter observation periods, and as a result statistical significance will only be maintained if the volume of available data per unit of time increases accordingly. Such volumes may no longer be achievable on national levels.
Big data is likely to provide innovative solutions by enabling life insurers to detect new patterns (correlations) that are good predictors or indicators of insured events.7 The relevant data will increasingly become available through our consumption patterns, health records and the use of search engines. In the near future life insurers will no longer have to ask for the information they need (primary information) – for instance, through medical questionnaires. Instead, they will be able to infer it from their clients’ past behaviour, which will become fully observable in the form of the digital exhaust they leave (derivative information). The statistical methods linked to this new approach have also become known under the generic term “predictive modelling” (see Box 1).
Box 1 – Predictive modeling in medical underwriting
Predictive modelling, at least in numerical form, is like regression analysis. It works to estimate the relationships between independent variables (predictors) and a dependent variable (output). In life insurance, both biomedical and consumer behaviour models have been developed.10 The former use blood pressure, medical test results and family history (predictors) to predict mortality (output). For decades these predictors have formed an integral part of medical underwriting. Predictive modelling, however, additionally takes account of the simultaneous effect of the predictors as well as their interaction. A major characteristic of the biomedical models is that the predictors are fully accepted by customers as causal risk factors in relation to the dependent variable. The traditional application process, notably the obligation to fill in lengthy health questionnaires, has long been considered tedious by customers. As a result, life insurers are competing to make underwriting easier by using shorter health questionnaires or higher medical examination limits. Consumer behaviour models further this trend by using socio-economic data instead of medical data for their risk classifications. Using existing information means customers are spared completing health questionnaires. Incidentally, non-disclosure will no longer constitute a problem. The socio-economic predictors can, for instance, be related to the disease status (output) derived from health insurance claims. The results could subsequently be used to decide when to require additional medical underwriting and when to issue a policy without further assessment.
What is more, in a digitally connected world, life insurers will be able to get in touch with their (prospective) clients in a highly targeted manner, thereby reducing anti-selection. Thanks to the widespread use of smartphones, tablets and other Information and Communications Technologies (ICTs), relevant information can be made available in real time when and where it is needed. This will allow life insurers to keep up with the accelerating pace of social change.
Impact on life insurers
To some extent, the behaviouristic paradigm that was discussed in our previous Risk Insights article has reappeared through the back door. In the digital world, observed behaviour is increasingly considered as an incorruptible proxy for traditional predictors. In its various facets, it can therefore offer a useful indirect source for life insurers in search of inferential evidence about insured events. It can be either a predictor of events (e.g. the Internet search for a specific cancer in case of an imminent health claim) or an indicator that an event has already happened (e.g. buying patterns of pregnant women, the example discussed in our previous Risk Insights article). Moreover, the ability to digitally track behaviour can help to eliminate moral hazard and to provide incentives for insurance customers to actively reduce their insured risks.8
Does this mean that the expertise of actuaries and medical underwriters will no longer be needed? Undoubtedly, some of the work with which those experts have been busy will be delegated to ICTs. Consider, for instance, the growing use of medical underwriting software, which can process the bulk of medical questionnaires in life insurance applications. They leave underwriters more time to focus on difficult cases, as well as on research, in connection with evidence-based underwriting decisions.
Actuaries, too, have been increasingly relieved from a great deal of the computational work that had to be handled manually in pre-digital times. This has freed up capacity, which is being directed at new and complex tasks. For the foreseeable future, there may always be tasks, old and new, that remain inaccessible to ICTs and therefore will continue to provide employment for many years to come.9 One of these tasks could be to relate new information to the web of existing information in order to make sense of its empirical or theoretical content. Presumably, this will require more and more transdisciplinary skills.
Making decisions based on data
How can we make well-founded decisions in an accelerating digital world? Data patterns do not always tell the whole story. On the other hand, theory (knowledge) is not infallible either, as evidenced by the history of science. But it will likely increase the predictive value of data patterns if they can be supported by good explanations (theory). From a practical point of view, it seems therefore worthwhile to develop criteria for a cautionary use of big data as a guideline for action (see Figure 3).11
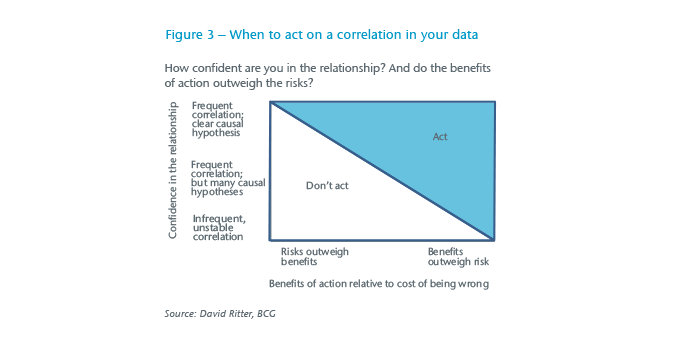
The risk of an action is, among others, determined by the severity of its possible consequences. The latter, in turn, depend on whether or not an action can be revised, and at what speed and cost. Take the contrast of mail-order selling with online shopping. Prior to the Internet, mail-order houses would send their customers catalogues. Any printing errors were costly as faulty copies needed to be replaced. Online shops can correct mistakes easily, just by using a few mouse clicks. We can assume that a higher proportion of our actions in the digital age will be revised, or reversed, at little or no cost, and in no time.
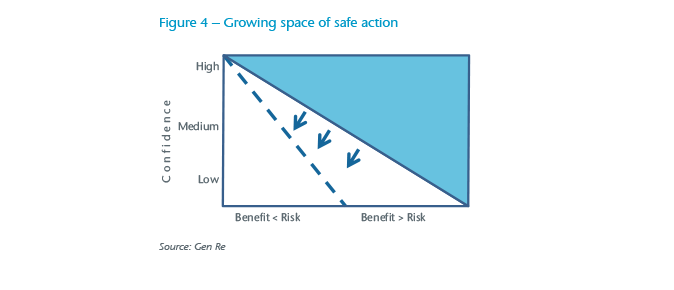
Therefore, the blue area in Figure 3, in which it is safe to act, is likely to expand further to the dotted line in Figure 4 as more and more people use ICTs, and their interconnectivity increases.
With the advent of big data, life insurers will have to carefully analyse and, possibly, redesign the touch points they have with their customers. For example, some trade-offs appear to be relevant when socio-economic data are used in the application and underwriting process:
- Reduced administrative expenses and elimination of non-disclosure versus higher anti-selection.
- Customer-friendly process versus opaque and hardly justifiable decisions when socio-economic data are used. The lack of causality in consumer behaviour models will make it difficult for applicants to accept an unfavourable risk classification.
The increased availability of personal data will likely make it possible to contact policyholders in a highly individualized manner, for example, when starting a new job or on the birth of a child. These touch points offer possibilities to create customer-friendly propositions that reduce the risk of anti-selection. Of course, it remains to be seen to what extent people are willing to accept greater proximity to their life insurer.
Conclusion
How will big data influence the major challenges of life insurers, such as responding better to customer needs, or the impact of technological and social changes, and even anti-selection or moral hazard?
Big data has further fuelled the acceleration of social change. In its wake, customers continuously reassess and redefine their needs. The interconnectivity of the digital world has sped up communication and services. As a result, consumers expect simple and quick solutions. This will reinforce the trend for less intrusive medical underwriting. The combined use of highly individualized touch points and objective socio-economic pricing data will contribute to further reduce anti-selection, and, possibly, help to create alternative selection protocols conserving traditional medical underwriting for only the highest sums insured.
Social change means that individuals’ biographies will likely be more fragmented. This might lead to a beneficial situation in which life insurers’ shrinking capacity for assuming long-term guarantees will meet with customers’ rising need for short-term solutions. It remains to be seen whether an increasing use of socio-economic data, not only at application but also in the pricing of products, will sooner or later collide with demands for transparency, fairness and solidarity.
In order to protect themselves against the growing risk of change, life insurers will have to diversify their portfolios as much as possible. On the other hand, enhanced technology will enable them to respond much faster to market changes than in the past. One thing appears to be beyond doubt: Uncertainty and risk will be there to stay, and with them the need for insurance.